文|时分线Timelines,作家|赵明,裁剪|周易
摩尔线程正在疼痛再行界说我方。
往日五年,摩尔线程被外界界说为一家国产GPU公司;但面前,摩尔线程正在挑升推翻这一定位。其中的一个典型例证是,在其上月召开的年度产物发布会上,摩尔线程用接近2个小时的时分,连气儿完成六大重磅发布:
从万卡级限制的夸娥智算集群,到自研“长江”SoC驱动的智能结尾MTTAICUBE和MTTAIBOOK;从数字天下智能体“小麦”,到加快物理AI落地的首个全栈具身智能仿真平台MTLambda,再到抓续进化的MUSA生态。
通过这一系列动态,摩尔线程全面展示了一个袒护“云-边-端”的全栈智算矩阵。

令东谈主见思意思的是,四肢外界领路中的一家典型的GPU公司,这场发布会上却莫得发布一款芯片产物,反而将触角延长到了具身智能、家居核心以及硬件层面。
是以,一个问题就当然披露了:这家以GPU为基本盘的公司,究竟念念要作念什么?
从万卡集群到十万卡
如若把时分的指针拨回到一年半以前,摩尔线程的叙事要点还十分肤浅——GPU。
2025年底,当摩尔线程登陆科创板时,支持其3000亿估值的核心钞票是夸娥(KUAE)万卡级智算集群——这是一套不错并行驱动数千致使上万颗GPU检修大模子的系统级处罚决策。
随后一年半,这套决策拿出了一组枢纽数据:Dense大模子检修中模子算力讹诈率(MFU)达60%,MoE大模子达40%,有用检修时长90%,8000卡限制的集群检修线性扩展后果达95%。“堆卡易,成阵难”——集群越大,系统越脆弱,一次链路抖动、交换机非常就可能触发四百四病。夸娥能跑出90%的有用检修时长,确认它在系统级工程材干上也曾跨越了国产GPU此前多量被诟病的“集群不行用”这谈坎。
2026年3月30日,摩尔线程签下了一笔6.6亿元的夸娥智算集群左券,单笔订单占2025年全年营收的44%。这是迄今为止国内算力市集最大的国产GPU单笔订单之一,解说了摩尔线程的产物也曾好像支持万卡级别的智算集群开垦。
4月26日,摩尔线程同期发布了2025年财报以及2026年一季度财报,进一步回答了云表基本盘的支持力。
财报炫耀,2025年营收15.06亿元,同比增长243.37%;2026年一季度营收7.38亿元,同比增长155.35%,归母净利润0.29亿元——这是摩尔线程自2025年12月科创板上市以来,初次在单季度已矣盈利。
基于这么的亮眼收获,张建中也在公开时事暗意,公司正在筹谋新一代十万卡级智算集群。
这么的蔓延节拍折射出一种强烈的乐不雅预期——张建中判断,跟着以OpenClaw为代表的AgenticAI应用深远,Token浪掷量正呈指数级增长,日均浪掷量已从一年前的30万亿猛增至180万亿。
他以为智算期间需要建立“三大AI工场”——模子检修工场、Token坐蓐工场、智能体坐蓐工场——而夸娥集群的任务,即是同期支持这三种天悬地隔却又相互交汇的算力需求。
这套逻辑本人并莫得什么问题,但它变成了一个颇为奥秘的处境:如若摩尔线程要连续平定其云表基本盘,就必须在十万卡级集群的开垦上抓续进入。
财报数据炫耀,2025年,摩尔线程研发进入达13.05亿元,占营收比重86.68%——换言之,公司赚到的每100元里,有87元被再行进入研发。即便到了盈利显豁改善的2026年一季度,研发进入占比仍保管在50%掌握。这一比例,在A股整个上市公司中都属极高。相较而言,国内芯片龙头海光信息的研发进入占比约为18%,寒武纪约为50%,台积电约为8%。
开云kaiyun(中国)体育官网这意味着天文数字的老本开支;但仅靠靠GPU这条路能否支持摩尔的估值天花板,又是另一个值得追问的话题。
但摩尔线程的压力也不啻于此。
2023年于今,寰球正在资历一场有史以来限制最大的算力武备竞赛。检修一个顶级大模子,需要层见迭出的GPU集群——英伟达GPU由此变成了稀缺政策资源,价钱飞扬的同期还一卡难求。
对中国AI产业而言,这场算力竞赛的要紧性被罕见压力所放大。2022年于今,在地缘政事的影响下,英伟达的GPU险些无缘中国市集。这一配景下,国产GPU的政策价值从“可选项”变成了“必选项”。
在这个配景下,包括摩尔线程、壁仞科技、海光信息、天数智芯在内,一批国产GPU公司接踵登场——但在工夫变革和浓烈竞争的双重维度下,仅靠GPU来讲故事,显豁也曾不是摩尔线程的解法。
从GPU到智能SoC
如若把云表算力比作“超等大脑”,那么端侧产物即是AI触达每个东谈主的“神经末梢”。但GPU公司在端侧的布局,平日留步于提供AI推理芯片。摩尔线程的作念法不太相通。
发布会上,摩尔线程除了延续云表叙事外,重点推出了自研“长江”智能SoC芯片、基于它的MTTAICUBE家庭AI核心和MTTAIBOOKAI算力本、以及名为“小麦”的全域智能体和MTLambda具身智能仿真平台。

“长江”SoC不是一颗肤浅的GPU或NPU,而是一颗竣工的端侧AI野心芯片。它里面集成了CPU、GPU、NPU和VPU,异构AI算力达50TOPS,对标对象不是英伟达,而是高通、联发科致使英特尔的酷睿。
基于“长江”SoC,摩尔线程构建了一套竣工的产物矩阵:MTTAIBOOK(个东谈主AI算力本)、MTTAICUBE(家庭AI核心)和MTTE300(工业边际AI模组)。其中AICUBE定位“智能体+AIPC+AINAS”三合一,搭载全域智能体“小麦”,集成90余项系统器用和60余项妙技,支抓超36款APP跨应用适度。
再往上,是一整套软件栈,包括原生Linux操作系统、MTClaw智能体框架、PES应用市集,以及MUSACODEAI编程器用。
这套“芯片—操作系统—整机—智能体”的产物链条,也曾袒护了传统上由四类不同公司承担的变装:英伟达(GPU)、高通(端侧SoC)、联念念(PC整机)和微软(操作系统)。摩尔线程试图把这四件事打包成一个长入的故事——智能体期间的基础规范。
“通盘业界枯竭一个Linux原生的好产物”,张建中在产物发布会上暗意。
潜台词是智能体期间的电脑不应该再跑Windows。这个判断的凭证在于:OpenClaw主要跑在Linux上,AI检修框架原生跑在Linux上,大模子推理工作的部署环境也大多是Linux。如若智能体真的成为PC的主要责任负载,被Windows锁了近三十年的消费级PC市集,表面上存在松动的可能。
摩尔线程不是在作念一台“能跑AI的札记本”,市面上圈套今整个札记本都能跑AI。它念念作念的是“让AI跑得比Windows更顺畅的札记本”,然后靠“长江”SoC、AI操作系统和自家智能体框架这一整套组合,在Windows还没反馈过来的窗口期里,卡住一个新的生态位。
这个判断是否能设置,将取决于两个枢纽变量:第一,对话式智能体是否真的成为主流交互样式;第二,尊龙凯时2026世界杯中国官网摩尔线程的AICUBE能否在被考证之前赢得弥漫的时分和用户。这是一个对于畴昔的押注,而任何押注都是有风险的。
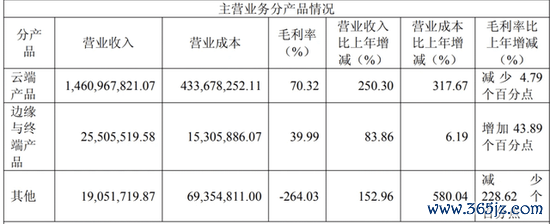
但这场押注也并非毫无根基。2025年财报炫耀,摩尔线程边际与结尾产物收入仅2550.55万元,占总营收的1.70%。险些不错忽略不计。
这意味着,从云表切入端侧,不是因为它也曾作念大了端侧市集,而是因为它必须用端侧的故事,大开估值念念象的第二弧线。在纯GPU赛谈上,摩尔线程面临的不仅是英伟达的生态壁垒,还有国内敌手们在集群和软件栈上的贴身追逐。如若不主动拓展战场,单纯依赖夸娥集群的订单增长,很难撑起3000亿市值背后的增长预期。
是以,端侧不仅是产物线的延长,更是一张对冲估值风险的牌。
MUSA能否长出孤立开发者体系?
硬件不错追逐,生态若何建立?
往日几年,国产GPU已训戒证了硬件材干——通过架构迭代和工程优化,国产芯片好像交出高分答卷。但企业采购GPU从来不是只买一张卡,而是在押注其背后的软件生态和开发体系。
与英伟达构筑的CUDA护城河逻辑相似,摩尔线程深知单一硬件无法界说畴昔,因此打造了一个纵深极广的生态系统MUSA,底层集成了AI野心、3D图形渲染、高性能野心与智能视频编解码的全功能GPU,以全数据单位的兼容性将算力触角延长至科学野心、数字孪生、具身智能、量子野心乃至6G通讯与生物医药等前沿鸿沟。
MUSA(Meta-computingUnifiedSystemArchitecture)是摩尔线程自研的全功能GPU野心加快长入系统架构,涵盖芯片架构、请示集、编程模子、软件运转库及驱动枢纽框架。
值得暖热的是,MUSASDK5.1.0对标CUDA12.8,驱动与运转时层兼容接口数达到761,核心数学库已矣100%兼容,PyTorch全算子(3194个)100%袒护。这意味着寰球数百万PyTorch开发者险些无需修改代码,就能把模子移动到MUSA上运转。
另外,在面前最主流的两个大模子推理框架SGLang和vLLM上,MUSA都带来了好音讯:
SGLang方面,MUSA后规定式加入SGLang的官方支抓体系,联系代码也已见效合入SGLang干线。vLLM方面,MUSA成为vLLM的官方后端,并开源vLLM-MUSA,开发者可原生获取摩尔线程GPU加快材干。
与单纯地多支抓了一个框架比拟,加入大模子推理框架官方后端矩阵意味着,国产GPU在生态适配上领有更充分、更径直的兼容旅途。
此外,摩尔学院平台已会聚超45万名开发者与学习者,衔尾院校超200所。对于一个设置仅六年的公司,这个增长速率确乎不慢。但45万与CUDA数百万级的开发者限制之间仍然存在数目级的差距。
MUSA的的确挑战在于:依赖兼容CUDA,它的生态故事永久是一个奴隶者。
是以,对于摩尔线程来说,它的确需要建立的是孤立、专有的工夫体验,让路发者因为MUSA“作念某件事更浅易”而经受它,而不是因为它“兼容CUDA”。
高增长的另一面
对于摩尔线程来说,单季净利润转正被市集解读为枢纽拐点信号——但这个信号背后,其实也存在一些隐忧。
此前,摩尔线程在回报投资者发问时,将2025年收入高增归因于两层身分:一是AI大模子快速迭代、应用蔓延,带动GPU需求赶紧增长;二是高端GPU出口适度抓续收紧,为国产AI芯片大开了替代窗口。
从这个角度看,摩尔线程这轮收入放量,踩中的既是AI算力蔓延周期,亦然国产替代加快的产业契机。
关联词,需要小心的是,摩尔线程一季报炫耀,当期非不息性损益整个8364万元,其入网入当期损益的政府补助为7006万元,占比约84%。
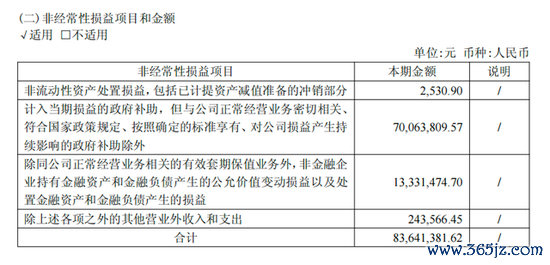
假如剔除上述状态,摩尔线程当季归母扣非净利润损失5428万元,固然同比收窄60.1%,但损失依然存在。
换言之,此次的账面盈利,是通过政府补贴,才跨越了枢纽的盈亏线。当下,摩尔线程的主营业务自身尚未已矣相差均衡。
对于摩尔线程来说,的确需要破局的,是能否舒缓把收入开端延长到更芜俚的买卖客群,需要在两方面同步推动:率先是产物质能和相识性的抓续提高,其次是MUSA软件生态的开发者限制蔓延。
而从芯片到集群,从集群到软件,从软件到结尾,从结尾到Agent,再从Agent到具身智能——这条链路拉得越长,竞争敌手追逐的难度就越大。
回头再看摩尔线程的旅途经受不错发现,这并非一条“GPU公司横向多元化”的惯例买卖蔓延,而是一家从GPU启程的硬科技公司,试图用我方最擅长的算力材干,向下扎到SoC,进取伸到OS和智能体的政策故事。
云表的夸娥集群,处罚的是“算力从哪来”的问题。“长江”SoC和AICUBE,处罚的是“算力到哪去”的问题。MUSA生态,处罚的是“开发者为什么留住来”的问题。智能体“小麦”和具身智能平台MTLambda,处罚的是“AI最终以什么形态触达物理天下”的问题。
这四层逻辑为德不终紊,拼在一皆,是一张从硅片到场景、从检修到推理、从造谣到物理的竣工疆域。
把目光再放长久极少,摩尔线程押注的是一个根人道判断:AI野心不会永久停留在“检修大模子”这个单一场景里,它终将渗入进每一个结尾、每一个物理空间、每一次东谈主机交互。从这个角度来看,摩尔线程从云表向端侧的延长,并不是一家GPU公司的“跨界”,而是一次趁势而为的生态升维。
只是,要念念最终印证这个判断,摩尔线程需要的不单是是时分尊龙凯时2026世界杯中国官网,也需要一个好像抓续造血的买卖正轮回。